《Algorithms Fourth Edition》笔记,动态连通性问题
UnionFind
UnionFind即动态连通性问题,给定触点的数量后,给出一系列表示触点连接的整数对(用索引表示),找出其中多余(即在之前就能确定两触点相连)的连接。相连的触点组成一个连通分量,换句话说,若某一个整数对的两个触点已经在同一个连通分量里,则此连接是多余的。
- Union:连接两个触点,即合并它们所在的连通分量
- Find:返回某个触点所在的连通分量标识符
- Connected:返回布尔值,表示两个触点是否相连
最简单的想法(QuickFind算法)就是给每一个连通分量规定一个唯一的标识符,用数组储存(最开始时,每一个触点都是单独的连通分量),这样Find很简单,只需根据索引返回数组中的值即可。不过每次合并两个连通分量(Union)时,需要将一个连通分量的所有触点的标识符都改为和另一个连通分量的相同,这样每次都得遍历一次数组,效率比较低。
可以改变标识符的意义:若规定每一个触点的标识符为相同连通分量的另一个触点的索引,必定会存在唯一的一个触点的标识符为其自身,那么这个触点即为该连通分量的根,那么判断两个触点是否相连,即判断它们所在的连通分量的根是否相同。其实就是利用了树的的结构,这个算法叫QuickUnion算法,它的最坏情况是平方级别的。JAVA代码如下:
public class UnionFind {
private int[] id;
private int count;
public UnionFind(int n)
{
count = n;
id = new int[n];
for(int i = 0; i < n; i++)
{
id[i] = i;
}
}
public int Count()
{
return count;
}
public boolean Connected(int p, int q)
{
return Find(p) == Find(q);
}
public int Find(int p)
{
while(id[p] != p)
p = id[p];
return p;
}
public void Union(int p, int q)
{
int pid = Find(p);
int qid = Find(q);
if(pid == qid)
return;
id[pid] = qid;
count--;
}
public static void main(String[] args)
{
int N = StdIn.readInt();
UnionFind UF = new UnionFind(N);
while(!StdIn.isEmpty())
{
int p = StdIn.readInt();
int q = StdIn.readInt();
if(UF.Connected(p, q))
continue;
UF.Union(p, q);
StdOut.println(p + " " + q);
}
StdOut.println(UF.Count());
}
}
在QuickUnion的基础上,可以进一步优化:由于利用了树的结构,所以每次Union时都是在将两棵树相连接,如果能保证总是将小树连接到大树,那么最终树的深度可以大大减少,这样触点Find的时候就更快了。具体的方法就是用一个数组储存根触点所在连通分量的树的大小(即树的结点的个数),然后在Union的时候判断一下即可。 这个算法叫做加权QuickUnion算法。
public class UnionFind {
private int[] id;
private int[] sz;
private int count;
public UnionFind(int n)
{
count = n;
id = new int[n];
sz = new int[n];
for(int i = 0; i < n; i++)
{
id[i] = i;
sz[i] = 1;
}
}
public int Count()
{
return count;
}
public boolean Connected(int p, int q)
{
return Find(p) == Find(q);
}
public int Find(int p)
{
while(id[p] != p)
p = id[p];
return p;
}
public void Union(int p, int q)
{
int pid = Find(p);
int qid = Find(q);
if(pid == qid)
return;
if(sz[pid] < sz[qid])
{
id[pid] = qid;
sz[qid] += sz[pid];
}
else
{
id[qid] = pid;
sz[pid] += sz[qid];
}
count--;
}
public static void main(String[] args)
{
int N = StdIn.readInt();
UnionFind UF = new UnionFind(N);
while(!StdIn.isEmpty())
{
int p = StdIn.readInt();
int q = StdIn.readInt();
if(UF.Connected(p, q))
continue;
UF.Union(p, q);
}
StdOut.println(UF.Count());
}
}
算法性能比较
以访问数组的次数为成本模型(不论读写),记录每一个连接处理的时间(黑色点)以及此时的均摊成本(总时间除以当前已处理的连接数,红色点),以蓝色水平线为数值参考,获得如下图像:
QuickFind算法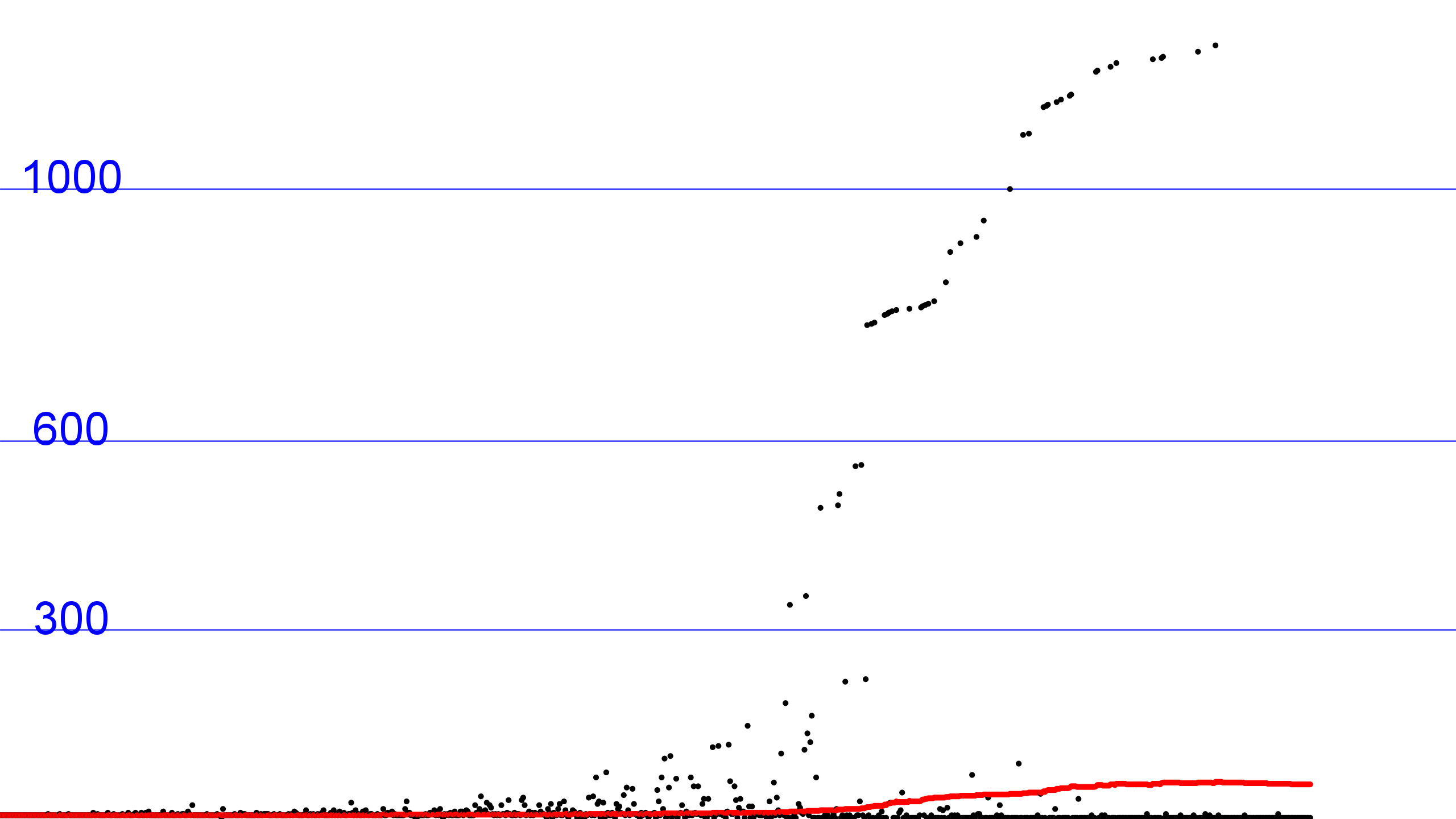
QuickUnion算法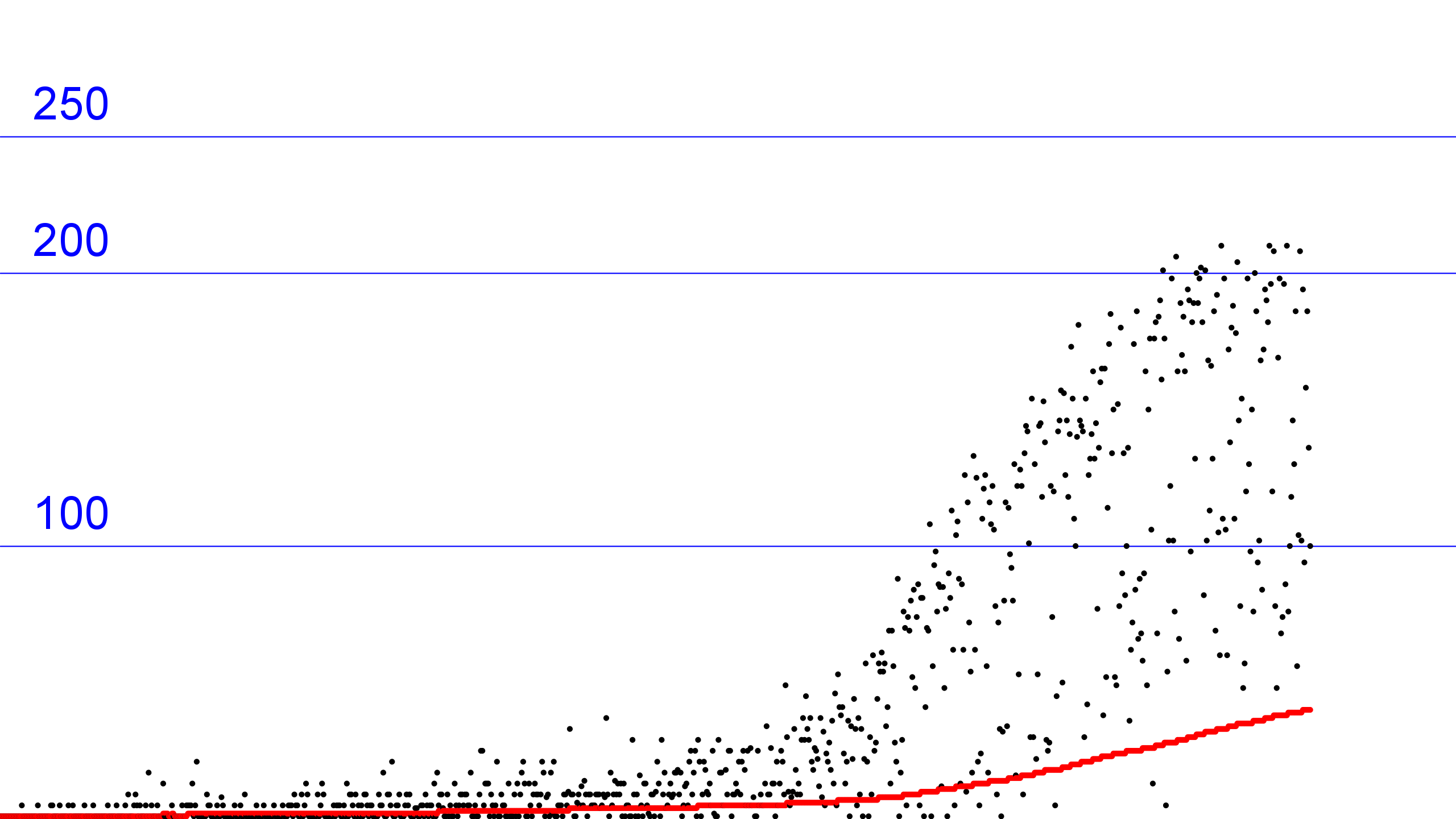
加权QuickUnion算法
可以看出,QuickFind算法在后面均摊成本开始下降,因为当连接数增多时,大部分连接都会跳过Union,而Connected所需的成本(两次Find)是比较低的,但Union遍历所需的成本还是很高。
而QuickUnion最开始时成本很低,但是随着树的深度不断增加,Find的成本越来越高,最后曲线开始大幅度上升。
而加权QuickUnion相对来说则几乎没有成本,因为基本解决了树的深度累加问题(树更加扁平了),所以后面也是保持稳定,几乎接近UnionFind的最优解了。
